Giới thiệu
Web Server
Web Server là gì
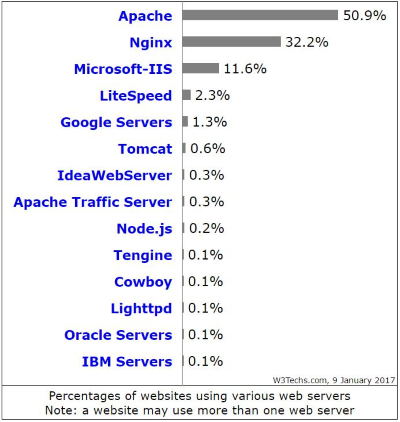
Web server là máy chủ cài đặt các chương trình phục vụ các ứng dụng web.Nó lưu trữ các tệp tài nguyên của trang web như HTML, CSS, JavaScript, hình ảnh và video,... Webserver có khả năng tiếp nhận request từ các trình duyệt web và gửi phản hồi đến client thông qua giao thức HTTP hoặc các giao thức khác. Có nhiều web server khác nhau như: Apache, Nginx, IIS, … Web server thông dụng nhất hiện nay:
Web server hoạt động như thế nào
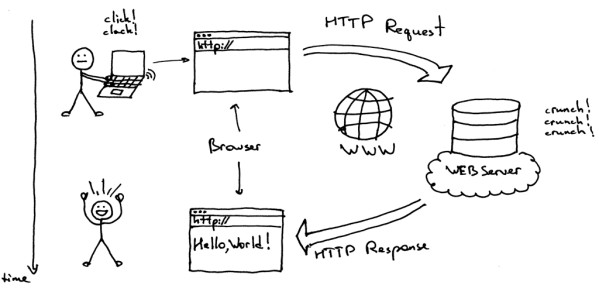
Khi một người dùng nhập địa chỉ URL vào trình duyệt, trình duyệt sẽ gửi một yêu cầu HTTP tới web server. Web server nhận yêu cầu, tìm kiếm tài nguyên được yêu cầu và gửi lại phản hồi chứa tài nguyên đó tới trình duyệt. Trình duyệt sau đó sẽ hiển thị trang web cho người dùng.
Bất cứ khi nào bạn xem một trang web trên internet, có nghĩa là bạn đang yêu cầu trang đó từ một web server. Khi bạn nhập URL trên trình duyệt của mình (ví dụ: https://github.com/Hehe-Boiz) nó sẽ tiến hành các bước sau để gửi lại phản hồi cho bạn.
-
Trình duyệt phân giải tên miền thành địa chỉ IP
Trình duyệt của bạn sẽ cần phải xác định địa chỉ IP nào mà tên miền github.com/Hehe-Boiz trỏ vào. Để làm việc đó trình duyệt sẽ thục hiện các bước:
- Trình duyệt kiểm tra bộ nhớ cache nội bộ: Trước tiên, trình duyệt kiểm tra xem liệu địa chỉ IP của tên miền đã được lưu trong bộ nhớ cache của nó hay chưa.
- Kiểm tra bộ nhớ cache hệ điều hành: Nếu nó không tìm thấy, nó sẽ hỏi hệ điều hành. Hệ điều hành có thể đã lưu trữ địa chỉ IP này trong bộ nhớ cache của mình.
- Yêu cầu đến máy chủ DNS: Nếu cả 2 đều không, yêu cầu sẽ được gửi tới máy chủ DNS. Máy chủ DNS sẽ tìm kiếm và trả về địa chỉ IP tương ứng với tên miền.
- Quá trình phân giải DNS: Nếu máy chủ DNS không có thông tin, nó sẽ liên hệ với các máy chủ DNS khác (những máy chủ DNS cấp cao hơn) để lấy địa chỉ IP.
-
Web Server gửi lại client trang được yêu cầu
Lúc này trình duyệt web đã biết địa chỉ IP của trang web, nó sẽ gửi một yêu cầu HTTP tới web server thông qua địa chỉ IP này.Web server xử lý và trả lại trang được yêu cầu theo các bước:
- Nhận yêu cầu: Yêu cầu này bao gồm phương thức (như GET hoặc POST), URL,...và các thông tin khác.
- Tìm kiếm tài nguyên: Server tìm tài nguyên yêu cầu (ví dụ: file HTML, JavaScript, hình ảnh,...) trong hệ thống tệp của mình.
- Xử lý yêu cầu: nếu cần, có thể thực hiện thêm các bước xử lý dữ liệu (chạy mã, truy vấn database,...).
- Gửi phản hồi: Sau khi tìm thấy hoặc tạo ra tài nguyên, web server gửi lại phản hồi HTTP tới trình duyệt. Phản hồi này bao gồm mã trạng thái (như 200 OK), nội dung trang web,...
Nếu trang không tồn tại hoặc có lỗi khác xảy ra, nó sẽ gửi lại thông báo lỗi thích hợp.
-
Trình duyệt hiển thị trang web
Khi nhận được phản hồi từ web server, trình duyệt bắt đầu quá trình hiển thị trang web cho người dùng. Theo các bước.
- Phân tích HTML: Trình duyệt phân tích tài liệu HTML để xây dựng cây DOM.
- Yêu cầu tài nguyên bổ sung: khi trình duyệt phát hiện các tài nguyên bổ sung (như CSS, JavaScript,..) và gửi các yêu cầu HTTP để tải chúng.
- Xây dựng CSSOM: Trình duyệt phân tích các tệp CSS để xây dựng cây CSSOM.
- Thực thi JavaScript: quá trình có thể thay đổi cây DOM và CSSOM.
- Kết hợp và hiển thị: Trình duyệt kết hợp cây DOM và CSSOM để xây dựng cây render, và hiển vị trang theo yêu cầu.
Quá trình này diễn ra rất nhanh, thường chỉ mất vài giây hoặc thậm chí mili giây.
Apache
Lịch sử và đặc điểm của Apache
Lịch sử hình thành
Apache HTTP Server, thường được gọi là Apache phát triển bởi Apache Software Foundation và ra mắt lần đầu tiên vào năm 1995.Nó nhanh chóng trở thành web server phổ biến nhất trên Internet nhờ tính ổn định, linh hoạt và hỗ trợ cộng đồng mã nguồn mở mạnh mẽ.
Đặc điểm
- Mã nguồn mở: Apache là phần mềm mã nguồn mở
- Đa nền tảng: Apache có thể chạy trên nhiều hệ điều hành khác nhau, bao gồm Unix, Linux, Windows và macOS
- Đa mô-đun: Apache hỗ trợ nhiều mô-đun mở rộng, giúp bổ sung các tính năng như bảo mật, quản lý phiên.
- Cấu hình linh hoạt: Apache cho phép tùy chỉnh cấu hình chi tiết thông qua các tệp như `httpd.conf` và `.htaccess`.
Ưu điểm và nhược điểm của Apache
Ưu điểm
- Tính ổn định cao: Apache đã được phát triển và cải tiến qua nhiều năm, mang lại sự ổn định và tin cậy cao cho các trang web.
- Hỗ trợ cộng đồng mạnh mẽ: Là một dự án mã nguồn mở, Apache có một cộng đồng phát triển lớn và sôi động, cung cấp nhiều tài liệu và hỗ trợ.
- Tính linh hoạt, thân thiện với người dùng: Apache hỗ trợ nhiều mô-đun mở rộng, cho phép dễ dàng tùy chỉnh và mở rộng tính năng.
- Bảo mật: Apache cung cấp nhiều tính năng bảo mật như SSL/TLS, xác thực người dùng và quản lý quyền truy cập, giúp bảo vệ trang web trước các mối đe dọa.
- Hiệu suất tốt: Apache có khả năng xử lý lưu lượng truy cập lớn và có thể được tối ưu hóa để cải thiện hiệu suất.
- Tích hợp tốt với các công nghệ khác: Apache dễ dàng tích hợp với nhiều ngôn ngữ lập trình và công nghệ web khác như PHP, Python, và Perl.
Nhược điểm
Bên cạnh những ưu điểm có thể nói gần như là hoàn hảo như thế thì vẫn tồn tại vài nhược điểm:
- Hiệu suất và Tính mở rộng: Apache có thể gặp khó khăn với hiệu suất và khả năng mở rộng khi xử lý nhiều yêu cầu đồng thời. Điều này chủ yếu là do cách nó xử lý các kết nối, đặc biệt là khi sử dụng mô hình multi-processing.
- Tài nguyên: Apache tiêu tốn nhiều tài nguyên hệ thống so với một số máy chủ web khác như Nginx, đặc biệt là khi xử lý nhiều yêu cầu kết nối đồng thời
- Khả năng cấu hình: Dù Apache rất linh hoạt, nhưng cấu hình của nó có thể trở nên phức tạp và khó quản lý khi có nhiều mô-đun và tùy chọn. Và khi quá nhiều lựa chọn thiết lập có thể gây ra các điểm yếu bảo mật.
- Quản lý kết nối: Apache xử lý kết nối bằng cách tạo ra một luồng hoặc tiến trình cho mỗi kết nối, điều này có thể không tối ưu cho các ứng dụng yêu cầu xử lý một lượng lớn kết nối đồng thời.
- Hỗ trợ cho WebSocket: Apache không hỗ trợ WebSocket trực tiếp, điều này có thể cần đến các mô-đun bổ sung hoặc cấu hình phức tạp hơn để triển khai.
Cách Apache hoạt động
Apache hoạt động theo kiến trúc đa tiến trình (multi-process), hướng kết nối (connection-oriented). Kiến trúc này có thể hiểu là mỗi yêu cầu sẽ được xử lý bởi một tiến trình riêng biệt hoặc một thread riêng biệt, tùy thuộc vào cấu hình Multi-Processing Module (MPM) được sử dụng như: prefork MPM, worker MPM, Event MPM. Mỗi tiến trình hoặc thread này được gọi là một Worker, có khả năng xử lý một kết nối tại một thời điểm.
Chi tiết các bước
-
Khởi động và Cấu hình
- Khi Apache khởi động nó tạo ra một tiến cha được gọi là tiến trình chính (parent process) dựa trên các cấu hình trong tệp `httpd.conf`.
- Tiến trình chính có nhiệm vụ đọc cấu hình và quản lý các tiến trình con (child processes).
-
Tạo Tiến trình Con và Luồng
- Tiến trình cha sẽ tọa ra một số tiến trình con. Số lượng này được xác định bởi các thông số cấu hình như `StartServers`, `MinSpareThreads`, `MaxSpareThreads`, và `MaxRequestWorkers`.
- Tùy vào cấu hình MPM mà tiến trình có tạo ra luồng hay không. Mỗi tiến trình con tạo ra nhiều luồng (threads). Số lượng luồng trong mỗi tiến trình con được cấu hình bởi tham số `ThreadsPerChild`.
-
Lắng nghe Yêu cầu
- Tiến trình chính mở các cổng để lắng nghe các kết nối HTTP/HTTPS, thường là cổng 80 cho HTTP và cổng 443 cho HTTPS.
- Tiến trình con và các luồng trong đó cũng sẽ lắng nghe các kết nối đến từ client
-
Xử lý Yêu cầu
- Khi một yêu cầu đến, một luồng trong một tiến trình con hoặc 1 tiến trình con sẽ nhận yêu cầu đó.
- Luồng (tiến trình con) này sẽ phân tích yêu cầu HTTP để xác định tài nguyên được yêu cầu, như tệp tĩnh (HTML, CSS, JS) hoặc tệp động (PHP, Perl).
- Nếu là tệp tĩnh, luồng sẽ đọc tệp từ source code và gửi lại nội dung cho client
- Nếu là tệp động, Apache sử dụng các module như mod_php để xử lý và tạo ra nội dung động, sau đó gửi kết quả về cho client.
-
Gửi Phản hồi
- Sau khi xử lý yêu cầu, luồng sẽ tạo phản hồi HTTP bao gồm mã trạng thái, tiêu đề, và nội dung.
-
Ghi Log
- Apache ghi lại thông tin về mỗi yêu cầu và phản hồi vào tệp log (access log và error log)
- Thông tin được ghi vào tệp log bao gồm địa chỉ IP của client, thời gian, phương thức yêu cầu, URL, mã trạng thái, và kích thước của phản hồi.
-
Quản lý Kết nối
- Sau khi gửi phản hồi, luồng có thể đóng kết nối hoặc giữ nó ở trạng thái mở (Keep-Alive) để xử lý các yêu cầu tiếp theo từ cùng một client.
- Nếu kết nối được giữ ở trạng thái mở, luồng sẽ tiếp tục chờ và xử lý các yêu cầu tiếp theo trên cùng kết nối đó.
-
Dọn Dẹp và Chuẩn Bị Cho Yêu Cầu Tiếp Theo
- Sau khi hoàn thành xử lý xong một yêu cầu, luồng sẽ dọn dẹp tài nguyên và chuẩn bị để xử lý các yêu cầu tiếp theo.
Bài viết và web tham khảo :
- https://vietnix.vn/apache-la-gi/
- https://topdev.vn/blog/web-server/
- https://chat.openai.com/
- https://claude.ai/new